The Importance of Dataloader in GraphQL (Go)
Go-GraphQL with Dataloader Implementation

In this article, I will discuss the implementation of the dataloader on GraphQL especially when we are using the Gqlgen library, so I will start a little explanation about GraphQL and Dataloader Concept.
What is GraphQL?
GraphQL is an API architecture that uses a query language to get the data. Clients have the freedom to ask for predictable data that ‘they need’ instead of returning the same structure of response (REST API) and another thing to be noted is that GraphQL only uses 1 endpoint instead of multiple like REST.

For example when we create REST API to get all users and the items that they have, first we will query all the users from the database, query the items of all users selected and return it as a JSON response, but what if the client doesn’t need the ‘items’ data. It will waste the query of our database. GraphQL has the advantage in this thing because the client can exclude items from the request so our server will only get all users and return it as the response, and if the client requests the items, then it will be executed by our server.
The disadvantage of GraphQL is the error code. GraphQL returns the error in the response and the status code will still be 200. Well if you are familiar with React and Apollo the error handling for GraphQL requests is provided by the library itself.
GraphQL Dataloader Concept
Dataloader is a concept to simplified our API data fetching by batching or caching it from a data source for example a database.
For example from the previous query, when we query all users from the database the SQL syntax would look like this SELECT * FROM users; and then how can you get the Items from each user?
There are two ways:
- Iterate through each user and query
SELECT * FROM items where user_id = $user_idand plug it into the user - Query All Items that related to selected users
SELECT * FROM items where user_id IN ($array_user_id)and then map them back into the corresponding user
Of course, the result of this two will be the same. But what if we compare the efficiency?
The first one will take the total query of database ’N’ which come from the number of users selected, and ‘1’ Which come from the GetAllUser: N + 1
The second one will take the total query of ‘1’ which come from the GetAllUser and ‘1’ from SELECT items where users_id in (...): 1 + 1 = 2
With the above complexity, we sure know that the second approach is better than the first one because of the total database query. This problem is also known as N + 1 Problem.
That’s what we are gonna implement a dataloader in our GraphQL to avoid this problem.
Requirement
- github.com/99designs/gqlgen
- github.com/vektah/dataloaden
- gorm.io/gorm
- github.com/gorilla/mux
- docker & docker-compose (MySQL database)
A basic of go programming is enough and some GraphQL knowledge, you can follow along with the step I provided or clone the complete repository.
Repository:
ERD

We will use this database concept for our dataloader example.
Hands On
We will create our project directory and initialize go modules.
$ mkdir gqlgen-dataloader-tutorial && cd gqlgen-dataloader-tutorial && go mod init myapp# Initialize gqlgen server
$ go get github.com/99designs/gqlgen
$ go run github.com/99designs/gqlgen init
Now your directory should look like this
.
├── go.mod
├── go.sum
├── gqlgen.yml
├── graph
│ ├── generated
│ │ └── generated.go
│ ├── model
│ │ └── models_gen.go
│ ├── resolver.go
│ ├── schema.graphqls
│ └── schema.resolvers.go
└── server.goBecause by default gqlgen ‘ID’ will be converted to ‘string’ we will change it to ‘int’ to match our database, follow the instruction below:
- go to
gqlgen.yml-> this is the configuration file for gqlgen. - Swap 48 & 49 line.
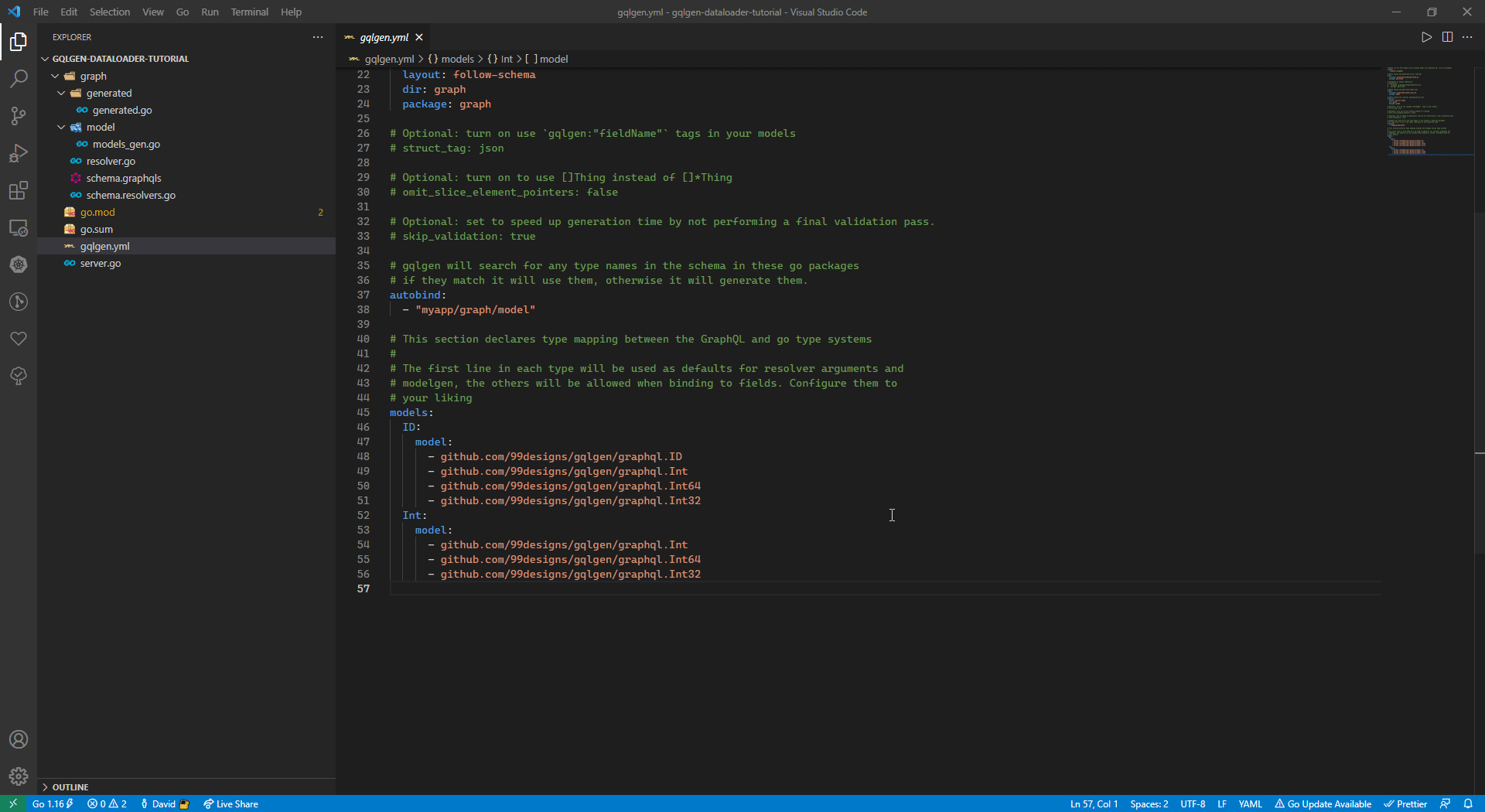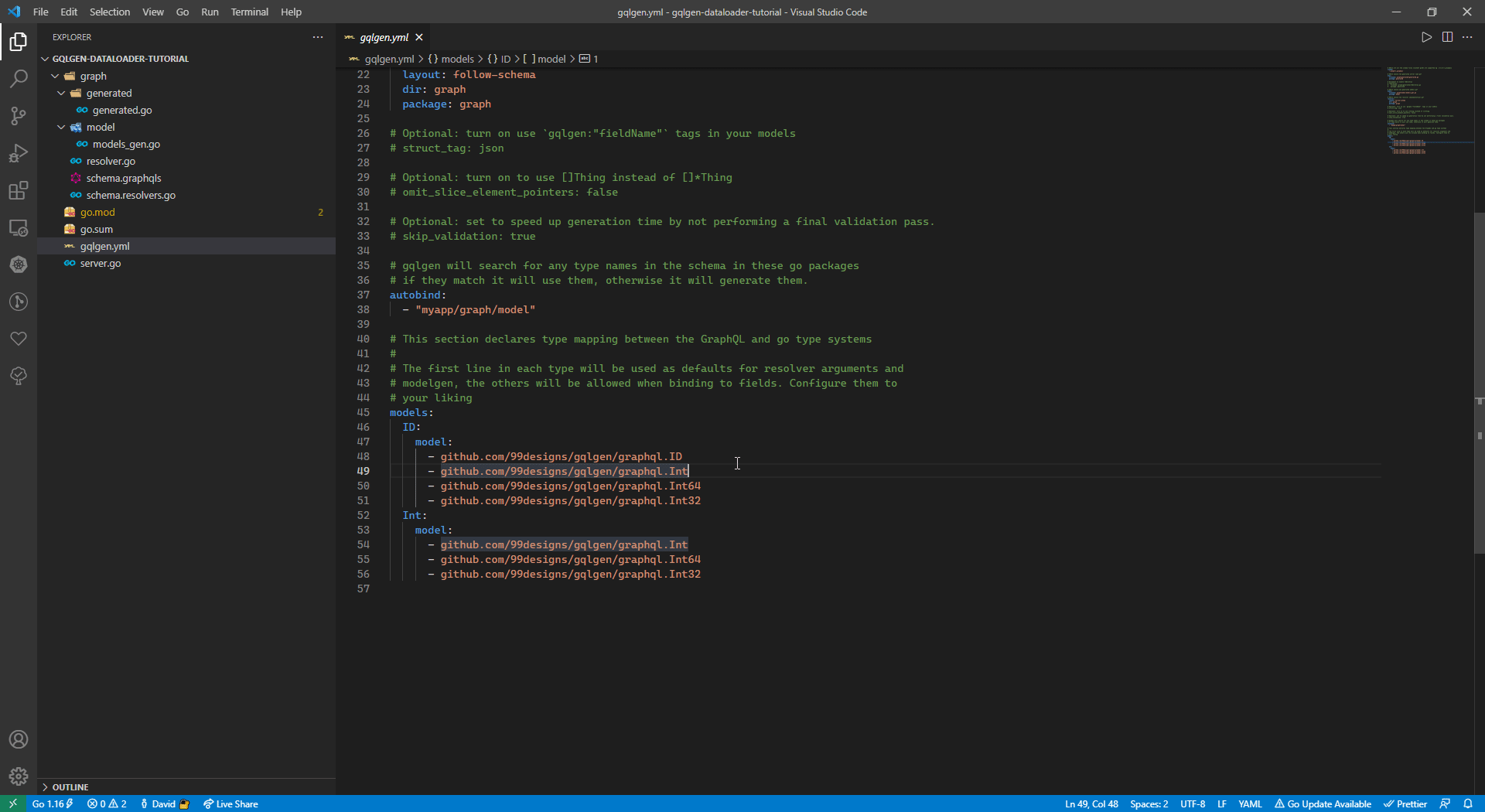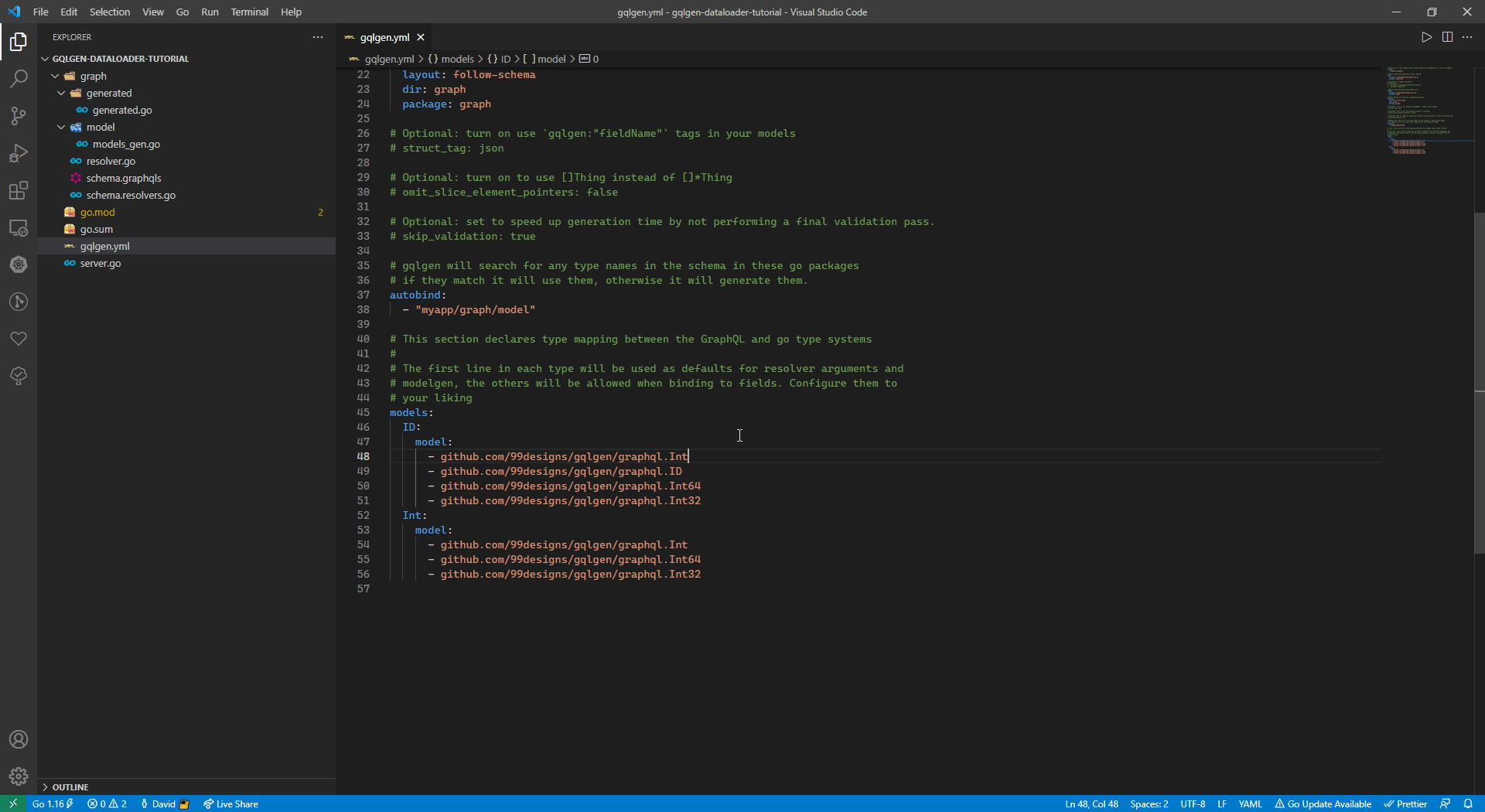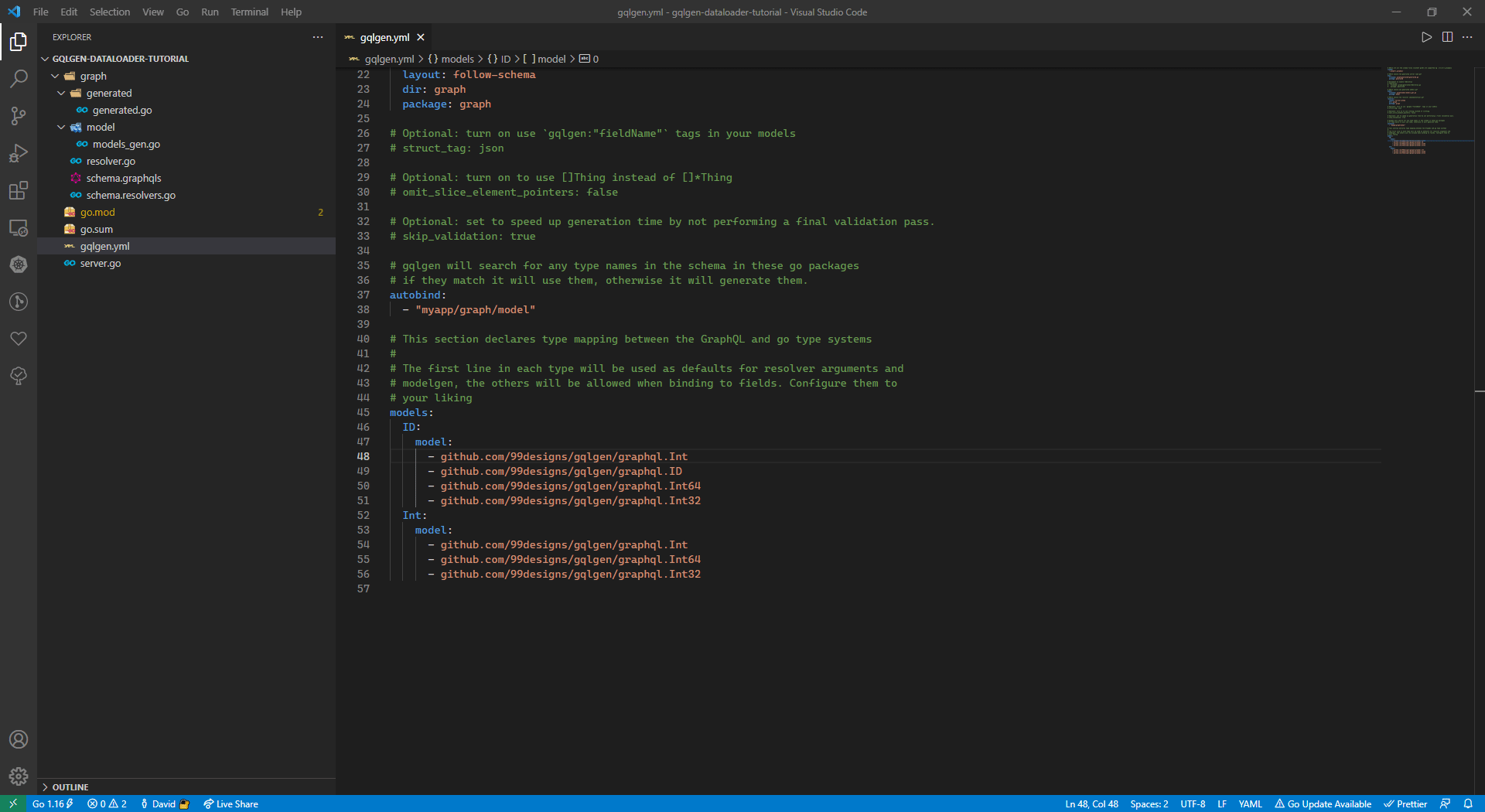
After we change this thing, the generated type of ‘ID’ will become ‘int’ instead of ‘string’
Next, we will create User, Transaction, TransactionDetails GraphQL Schema and add goField; gqlgen build-in directives.
graph/schema.graphqls
We declare the goField directive on line 6, this will help us to force generate a resolver from a section. And then we will add scalar Time which will allow us to use Time attributes later on that will be generated as time.Time.
In the Query the section we add all Read things so we can test it on later for dataloader case, and Mutation to help us insert data.
graph/user.graphqls
In the User object, we add transactions as a goField , we will apply the dataloader here. UserOps to grouping the User mutation. The same goes for Transaction and TransactionDetail below.
graph/transaction.graphqls
graph/transactionDetail.graphqls
Instead of running go run github.com/99designs/gqlgen, you can simply add it into ‘go generate’.
Add this line into your graph/resolvers.go.
//go:generate go run github.com/99designs/gqlgen
To generate the code, you just need to run go generate ./... now.
And then after we generated it, there will be some leftover code at the end of graph/schema.resolvers.go file.
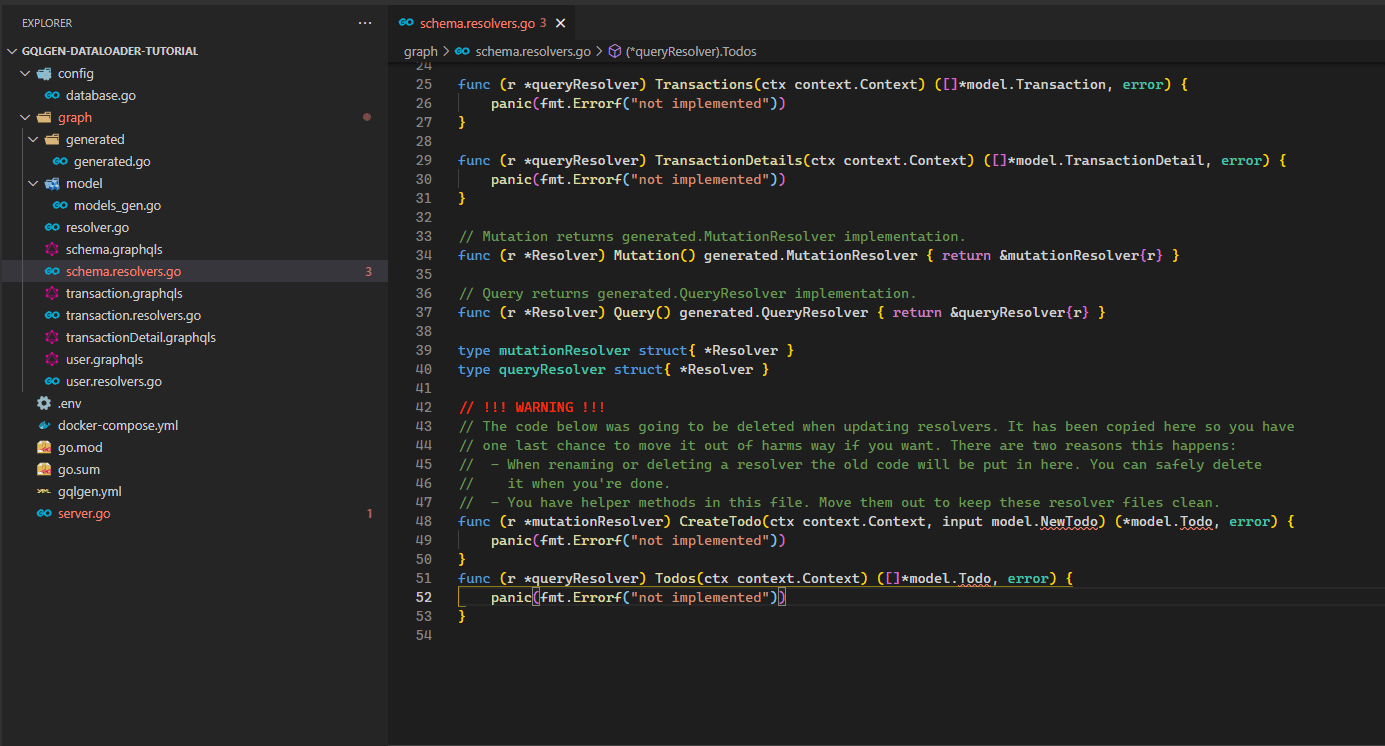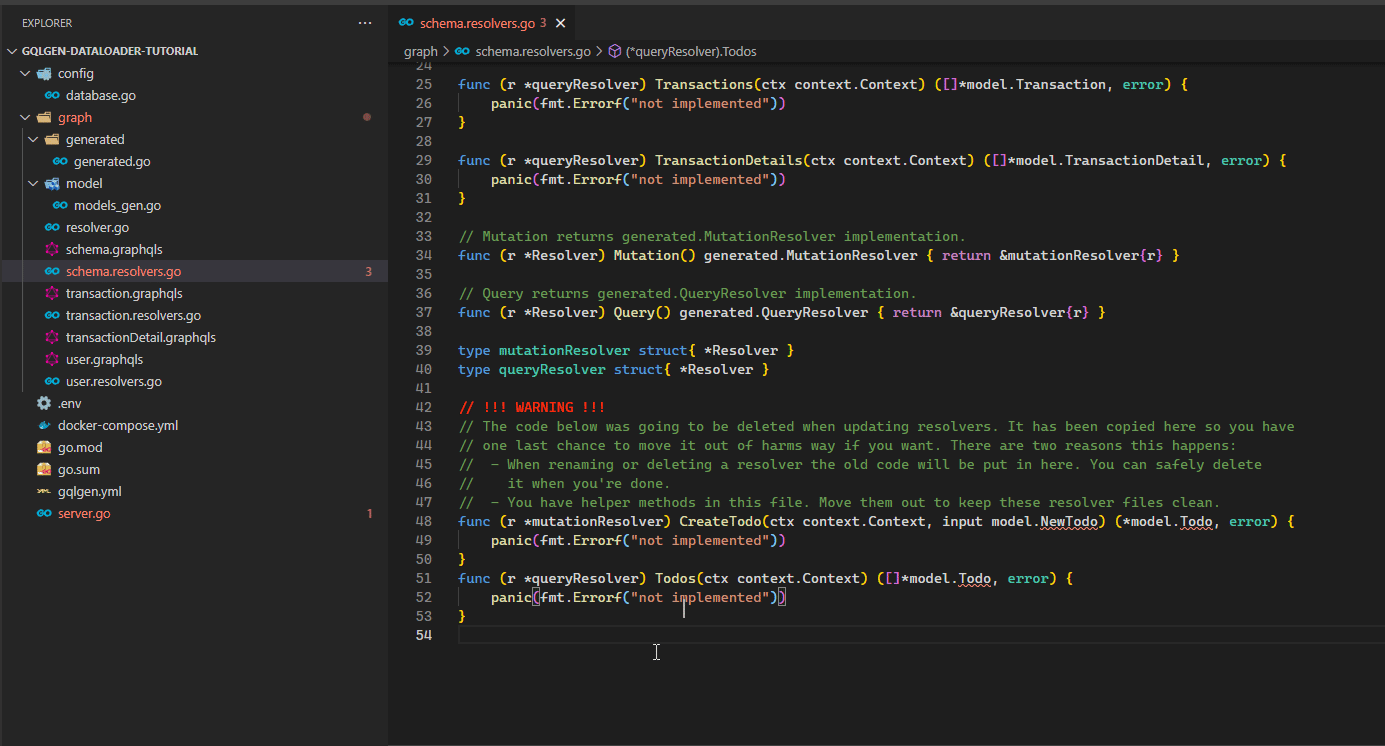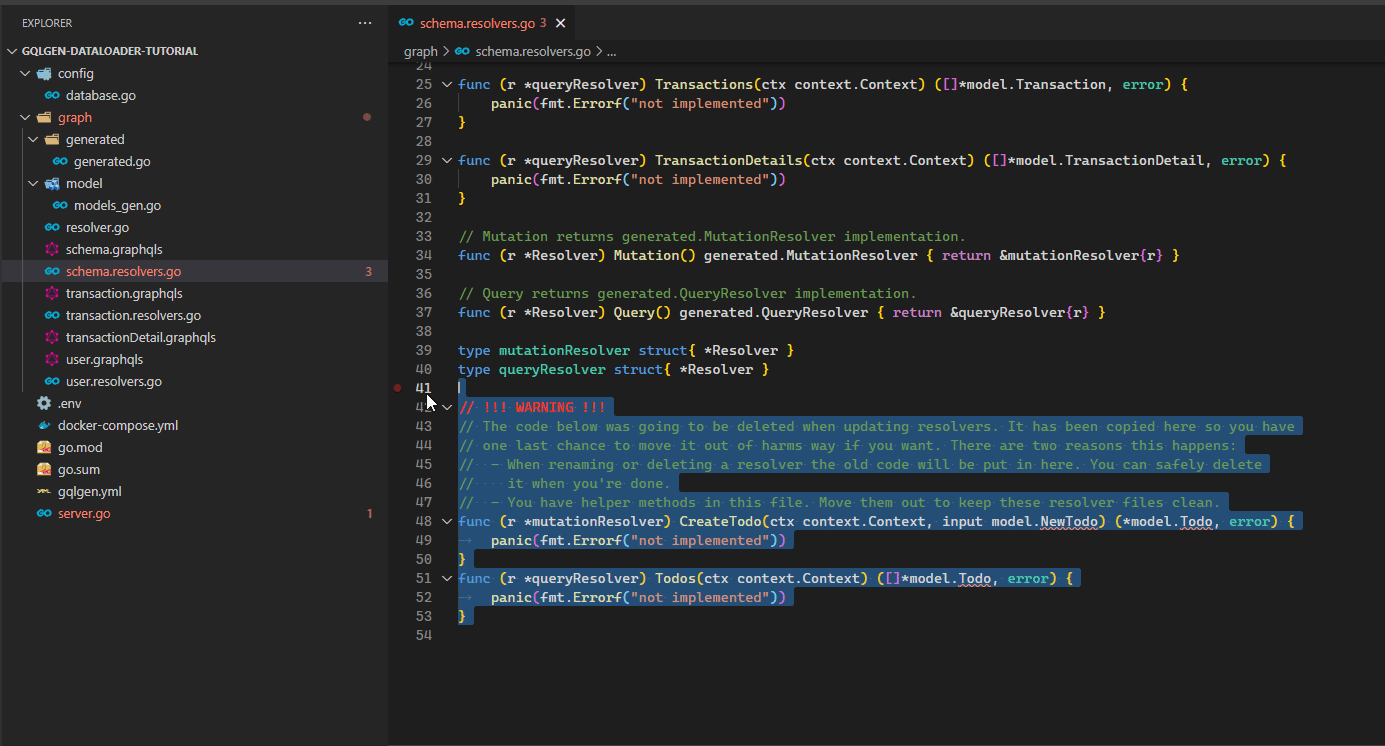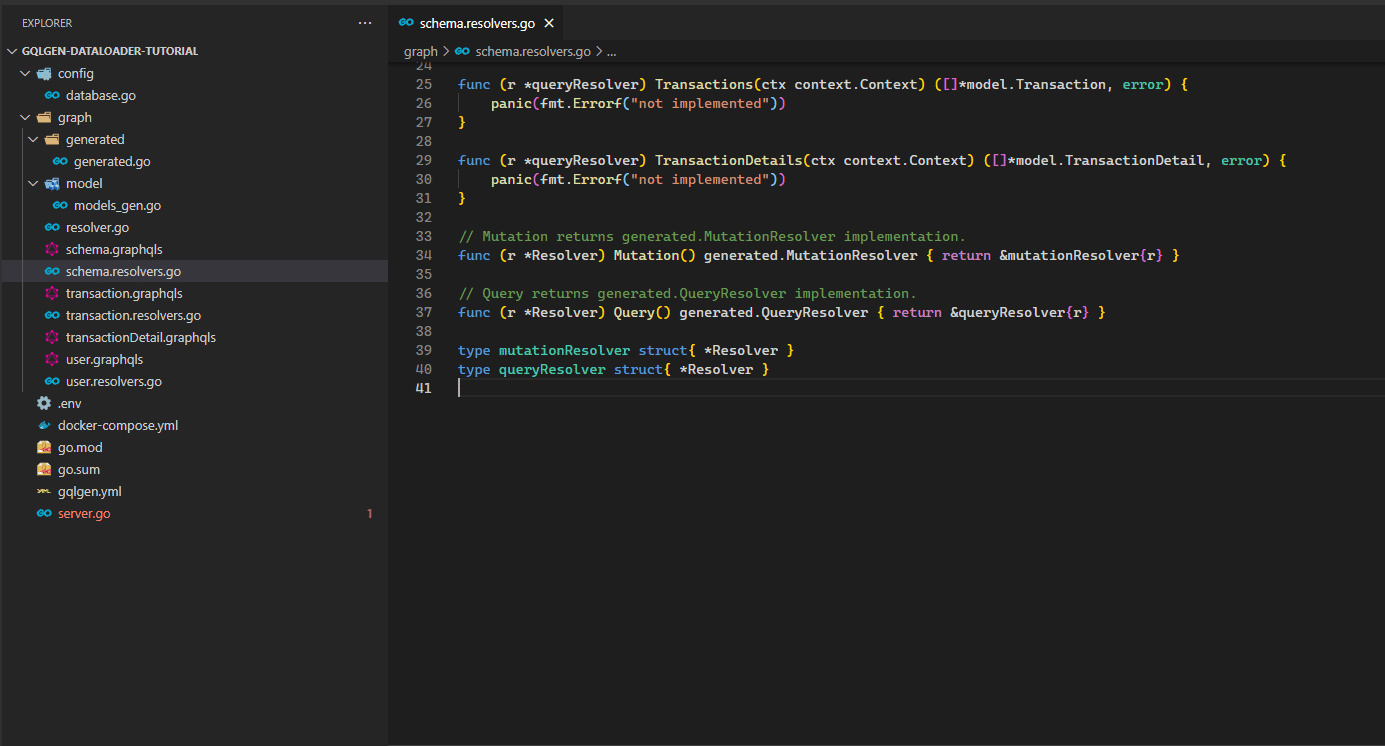
Why there is leftover code? Because from the previous graph/schema.graphqls we deleted it, so gqlgen is smart enough to leave the generated code instead of deleted it, so we can review it for the last time before deleting it (sometimes we generated something that we don’t want).
Database & Gorm Configuration
We will use docker & docker-compose to create a MySQL container.
This is the docker-compose.yml configuration:
docker-compose.yml
Other configurations and environments for the MySQL image are available at this website https://hub.docker.com/_/mysql. Start the container by running docker-compose up -d command.
Next, we will create our GORM connection, Gorm is a SQL ORM(Object Relational Mapping) for go. It helps us creating a more flexible way of writing database queries and maintaining our code better.
We will save the *gorm.DB as a global variable so other services can use a single open connection rather than open it every time we query a database. GetDB will be our ‘Getter’ for the global variable and ConnectGorm will be called in server.go at the beginning of the program, so the global db value will be initialized. About initConfig , initLog , and initNamingStrategy are just a configuration that I normally used. Keep in mind that we need to have the environment for the database, so let’s go and add it to .env
// .env
DB_HOST=127.0.0.1
DB_PORT=3306
DB_USER=root
DB_PASSWORD=
DB_DATABASE=graph_dataloaderFeel free to change the value if you have your own database configuration.
Now then, we need to add the config to server.go
For your information, init() function is a unique function, I will run first, even before ‘main’ starts, you can read more about it in this section. And godotenv.Load() it will load your .env to your application, the library is github.com/joho/godotenv and optionally you can defer Close() your database in the main() function.
Model & Migration
After we have a database Getter we can use it to help us Migrate the table for our model User , Transaction , and TransactionDetail . First, we need to drag the models out off models_gen.go to avoid overwritten by the generator and add gorm tag configuration on each attribute of the model. We will move it to graph/model/models_gorm.go
graph/model/models_gorm.go
Don’t forget to remove it from models_gen.go to avoid collision between models.
This tag gorm will be the config for the migration, you can learn more on this website https://gorm.io which is the official docs for GORM.
Then we will need a function MigrateTable , we will make it inside migration/migration.go
migration/migration.go
AutoMigrate is a gqlgen feature that helps us generate the table from gorm tag that we define previously. Of course, you can do it manually using Migrator , but I like AutoMigrate more than Migrator because it is more simple.
Then we apply this into our server.go
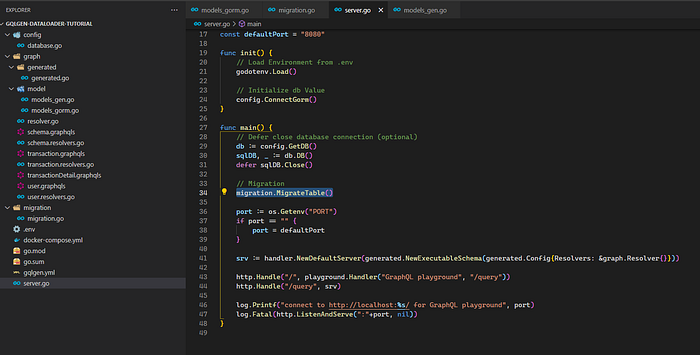
We are done with the migration part. Next, we will create the service for the models.
Create & Read Service
We only make Create & Read for this example because it is more than enough, update and delete will not be shown in this article.
We will start from User service
service/user.go
Just a simple UserCreate and UserGetAll , next for the Transaction
service/transaction.go
For transactions, we cover-up TransactionDetail inside TransactionCreate and we make TransactionGetAll for the resolvers, TransactionGetByUserID and TransactionGetByUserIds for the goField resolver and dataloader implementation later on.
And the last one is TransactionDetail .
service/transaction_detail.go
We don’t make the Create because it was cover inside the TransactionCreate and same as before, we make get function for resolvers, goField and dataloader.
Time to plug the function to the right resolvers.



And then we are ready to test our code (without a dataloader).
First Test (Without Dataloader)
go run server.go
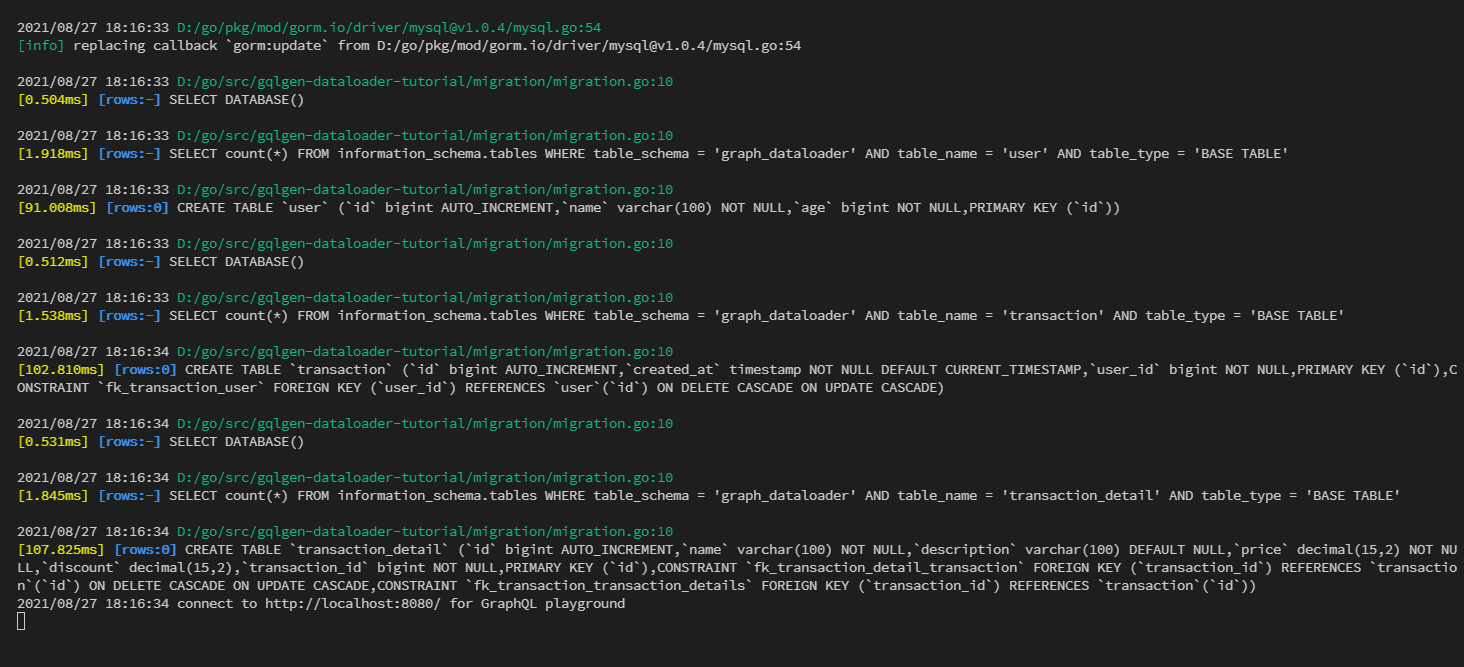
This is our log from the migration, which means our table is migrated successfully.
Then we will try to create some data in http://localhost:8080
## First User
mutation{
user{
create(input:{
name: "First"
age: 15
}){
id
name
}
}
}## response
{
"data": {
"user": {
"create": {
"id": 1,
"name": "First"
}
}
}
}## Second User
mutation{
user{
create(input:{
name: "Second"
age: 18
}){
id
name
}
}
}## response
{
"data": {
"user": {
"create": {
"id": 2,
"name": "Second"
}
}
}
}
From these mutations, we didn’t ask for transactions as the response of the query, so goField doesn’t run the resolver. That’s the advantage of GraphQL, we can run things that the client asks instead of querying all things and return it to the response.
Next, we will create some Transaction and TransactionDetail.
## Create Transaction
mutation{
transaction{
create(input: {
user_id: 1
transaction_details:[
{
name: "Golang Course"
price: 10000
discount: 5000
},
{
name: "Laravel Course"
price: 50000
}
]
}){
id
created_at
user_id
summary{
total_price
total_discount
transaction_details{
id
name
description
price
discount
transaction_id
}
}
}
}
}## Response
{
"data": {
"transaction": {
"create": {
"id": 1,
"created_at": "2021-08-27T11:24:23Z",
"user_id": 1,
"summary": {
"total_price": 60000,
"total_discount": 5000,
"transaction_details": [
{
"id": 1,
"name": "Golang Course",
"description": null,
"price": 10000,
"discount": 5000,
"transaction_id": 1
},
{
"id": 2,
"name": "Laravel Course",
"description": null,
"price": 50000,
"discount": null,
"transaction_id": 1
}
]
}
}
}
}
}
It works well. Now create several User , Transaction , TransactionDetails on your own, I suggest about 3 users, 3 transactions for each user, and about 2 transaction details for each transaction.
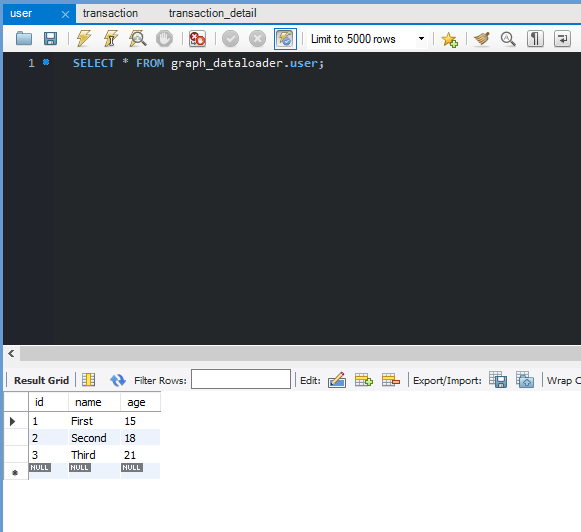

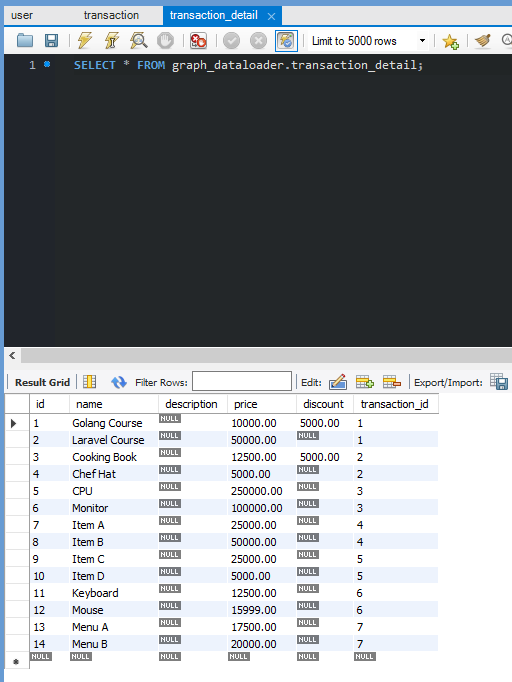
This is the data that I will use. So let’s start by analyzing our GORM log from the query.
## Query
query{
users{
id
name
age
transactions{
id
created_at
user_id
summary{
total_price
total_discount
transaction_details{
id
name
description
price
discount
transaction_id
}
}
}
}
}## response
{
"data": {
"users": [
{
"id": 1,
"name": "First",
"age": 15,
"transactions": [
{
"id": 1,
"created_at": "2021-08-27T11:24:24Z",
"user_id": 1,
"summary": {
"total_price": 60000,
"total_discount": 5000,
"transaction_details": [
{
"id": 1,
"name": "Golang Course",
"description": null,
"price": 10000,
"discount": 5000,
"transaction_id": 1
},
{
"id": 2,
"name": "Laravel Course",
"description": null,
"price": 50000,
"discount": null,
"transaction_id": 1
}
]
}
},
{
"id": 2,
"created_at": "2021-08-27T11:26:45Z",
"user_id": 1,
"summary": {
"total_price": 17500,
"total_discount": 5000,
"transaction_details": [
{
"id": 3,
"name": "Cooking Book",
"description": null,
"price": 12500,
"discount": 5000,
"transaction_id": 2
},
{
"id": 4,
"name": "Chef Hat",
"description": null,
"price": 5000,
"discount": null,
"transaction_id": 2
}
]
}
},
{
"id": 3,
"created_at": "2021-08-27T11:27:08Z",
"user_id": 1,
"summary": {
"total_price": 350000,
"total_discount": 0,
"transaction_details": [
{
"id": 5,
"name": "CPU",
"description": null,
"price": 250000,
"discount": null,
"transaction_id": 3
},
{
"id": 6,
"name": "Monitor",
"description": null,
"price": 100000,
"discount": null,
"transaction_id": 3
}
]
}
}
]
},
{
"id": 2,
"name": "Second",
"age": 18,
"transactions": [
{
"id": 4,
"created_at": "2021-08-27T11:27:34Z",
"user_id": 2,
"summary": {
"total_price": 75000,
"total_discount": 0,
"transaction_details": [
{
"id": 7,
"name": "Item A",
"description": null,
"price": 25000,
"discount": null,
"transaction_id": 4
},
{
"id": 8,
"name": "Item B",
"description": null,
"price": 50000,
"discount": null,
"transaction_id": 4
}
]
}
},
{
"id": 5,
"created_at": "2021-08-27T11:27:40Z",
"user_id": 2,
"summary": {
"total_price": 30000,
"total_discount": 0,
"transaction_details": [
{
"id": 9,
"name": "Item C",
"description": null,
"price": 25000,
"discount": null,
"transaction_id": 5
},
{
"id": 10,
"name": "Item D",
"description": null,
"price": 5000,
"discount": null,
"transaction_id": 5
}
]
}
}
]
},
{
"id": 3,
"name": "Third",
"age": 21,
"transactions": [
{
"id": 6,
"created_at": "2021-08-27T11:28:05Z",
"user_id": 3,
"summary": {
"total_price": 28499,
"total_discount": 0,
"transaction_details": [
{
"id": 11,
"name": "Keyboard",
"description": null,
"price": 12500,
"discount": null,
"transaction_id": 6
},
{
"id": 12,
"name": "Mouse",
"description": null,
"price": 15999,
"discount": null,
"transaction_id": 6
}
]
}
},
{
"id": 7,
"created_at": "2021-08-27T11:28:20Z",
"user_id": 3,
"summary": {
"total_price": 37500,
"total_discount": 0,
"transaction_details": [
{
"id": 13,
"name": "Menu A",
"description": null,
"price": 17500,
"discount": null,
"transaction_id": 7
},
{
"id": 14,
"name": "Menu B",
"description": null,
"price": 20000,
"discount": null,
"transaction_id": 7
}
]
}
}
]
}
]
}
}
From the response, we don’t see anything wrong right? The result is true, but the query of the database is the problem, let’s see this picture below.
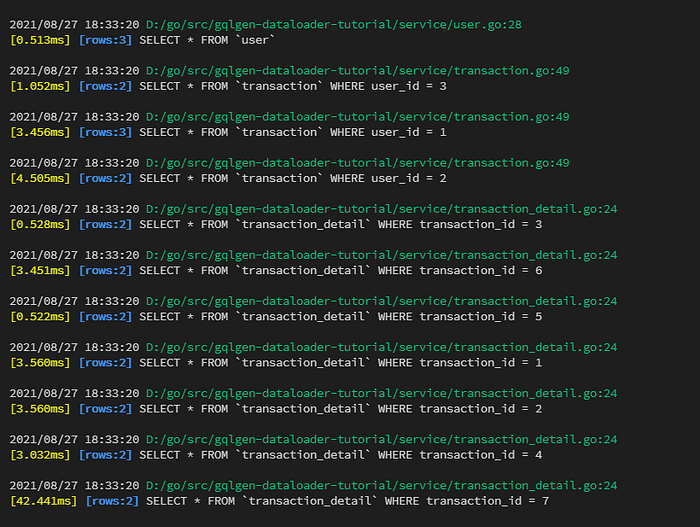
Many queries can be merged into 1 query for example
SELECT * FROM transaction_detail WHERE transaction_id IN (1,2,3,4,5,6,7)
will be a good choice instead of query it 7 times. But, how can we do it in GraphQL? How do we get all variables from 7 different resolvers?
That’s when the dataloader comes to rescue us from this N + 1 Problem in GraphQL.
So let’s move on to the Dataloader part.
Dataloader
mkdir dataloader && touch dataloader/dataloader.go
Inside the dataloader/dataloader.go we will insert this main Middleware and Context getter.
dataloader/dataloader.go
The system of the dataloader is to ‘wait’ for the parameter for 1 * time.Millisecond and start the query or the batch of the query exceeded 100 then we use our service to get the Object desired by each loader by ids so we will get an array of the item. How do we assign it back into each corresponding request? we will group it into the right array and return it, the dataloader will handle the rest for us.
Next, generate the dataloader
$ cd dataloader$ go run github.com/vektah/dataloaden TransactionDetailByIDLoader int []*myapp/graph/model.TransactionDetail$ go run github.com/vektah/dataloaden TransactionByIDLoader int []*myapp/graph/model.Transaction## Cd back to root
$ cd ..
Don’t forget to cd into the root directory of the folder later.
And then we will add dataloader Middleware into our server.go , we will apply mux for our router.
server.go
The last thing we need to do is to apply it to our resolvers. Follow the below code.
graph/user.resolvers.go
graph/transaction.resolvers.go
Explanation about the dataloader flow
- Before we process the request, the middleware will insert a
dataloader.Loadersobject inside the*http.Requestcontext (context.WithValue). - Later, on the resolvers, we called
dataloader.For(ctx)which will take the value of thedatalaoder.Loadersfrom thectxand then we are free to use the dataloader listed in ourLoaders.Loadfunction take the argument that we declare from the code we generate which isint.
Extras: about the dataloader generator format, it is.
go run ...../dataloaden {LoaderName} {KeyParam} {ReturnObject}Time for the second round.
Second Test (With Dataloader)
go run server.go
We will use the same query as before
## Query
query{
users{
id
name
age
transactions{
id
created_at
user_id
summary{
total_price
total_discount
transaction_details{
id
name
description
price
discount
transaction_id
}
}
}
}
}## response
{
"data": {
"users": [
{
"id": 1,
"name": "First",
"age": 15,
"transactions": [
{
"id": 1,
"created_at": "2021-08-27T11:24:24Z",
"user_id": 1,
"summary": {
"total_price": 60000,
"total_discount": 5000,
"transaction_details": [
{
"id": 1,
"name": "Golang Course",
"description": null,
"price": 10000,
"discount": 5000,
"transaction_id": 1
},
{
"id": 2,
"name": "Laravel Course",
"description": null,
"price": 50000,
"discount": null,
"transaction_id": 1
}
]
}
},
{
"id": 2,
"created_at": "2021-08-27T11:26:45Z",
"user_id": 1,
"summary": {
"total_price": 17500,
"total_discount": 5000,
"transaction_details": [
{
"id": 3,
"name": "Cooking Book",
"description": null,
"price": 12500,
"discount": 5000,
"transaction_id": 2
},
{
"id": 4,
"name": "Chef Hat",
"description": null,
"price": 5000,
"discount": null,
"transaction_id": 2
}
]
}
},
{
"id": 3,
"created_at": "2021-08-27T11:27:08Z",
"user_id": 1,
"summary": {
"total_price": 350000,
"total_discount": 0,
"transaction_details": [
{
"id": 5,
"name": "CPU",
"description": null,
"price": 250000,
"discount": null,
"transaction_id": 3
},
{
"id": 6,
"name": "Monitor",
"description": null,
"price": 100000,
"discount": null,
"transaction_id": 3
}
]
}
}
]
},
{
"id": 2,
"name": "Second",
"age": 18,
"transactions": [
{
"id": 4,
"created_at": "2021-08-27T11:27:34Z",
"user_id": 2,
"summary": {
"total_price": 75000,
"total_discount": 0,
"transaction_details": [
{
"id": 7,
"name": "Item A",
"description": null,
"price": 25000,
"discount": null,
"transaction_id": 4
},
{
"id": 8,
"name": "Item B",
"description": null,
"price": 50000,
"discount": null,
"transaction_id": 4
}
]
}
},
{
"id": 5,
"created_at": "2021-08-27T11:27:40Z",
"user_id": 2,
"summary": {
"total_price": 30000,
"total_discount": 0,
"transaction_details": [
{
"id": 9,
"name": "Item C",
"description": null,
"price": 25000,
"discount": null,
"transaction_id": 5
},
{
"id": 10,
"name": "Item D",
"description": null,
"price": 5000,
"discount": null,
"transaction_id": 5
}
]
}
}
]
},
{
"id": 3,
"name": "Third",
"age": 21,
"transactions": [
{
"id": 6,
"created_at": "2021-08-27T11:28:05Z",
"user_id": 3,
"summary": {
"total_price": 28499,
"total_discount": 0,
"transaction_details": [
{
"id": 11,
"name": "Keyboard",
"description": null,
"price": 12500,
"discount": null,
"transaction_id": 6
},
{
"id": 12,
"name": "Mouse",
"description": null,
"price": 15999,
"discount": null,
"transaction_id": 6
}
]
}
},
{
"id": 7,
"created_at": "2021-08-27T11:28:20Z",
"user_id": 3,
"summary": {
"total_price": 37500,
"total_discount": 0,
"transaction_details": [
{
"id": 13,
"name": "Menu A",
"description": null,
"price": 17500,
"discount": null,
"transaction_id": 7
},
{
"id": 14,
"name": "Menu B",
"description": null,
"price": 20000,
"discount": null,
"transaction_id": 7
}
]
}
}
]
}
]
}
}
The response is still the same as before, notice any difference?
If notice it, good. It is the database query. Let’s take a look at the log.
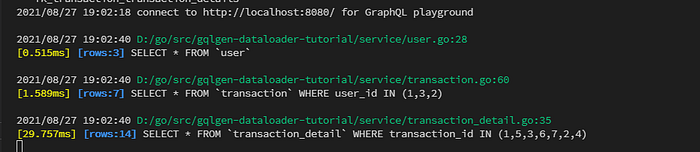
Conclusion
From the previous explanation, we can see that the dataloader has a big advantage in the implementation which makes our query faster. So it’s a good thing to learn and apply it to your next project.
Learn continually. There’s always “one more thing” to learn.”
— Steve Jobs
Hope this article helps you :).
